
Ranking products creates winners and losers. The product ranked #1 benefits; products ranked lower may complain or challenge your methodology. If your rankings are defensible—based on clear criteria, consistent evaluation, and transparent reasoning—you can withstand these challenges. If your rankings are based on vibes, affiliate commissions, or unstated preferences, you're vulnerable.
Beyond defensive value, systematic evaluation produces better content. When you've thought carefully about what matters and why, your rankings reflect genuine analysis rather than arbitrary ordering. Readers can tell the difference, and that trust translates into engagement, sharing, and return visits.
This pillar guide covers the complete tool evaluation framework: how to select criteria, weight factors, score consistently, prevent bias, and document methodology in ways that build authority. Whether you're ranking SaaS tools, physical products, or services, the framework applies.

Criteria Selection: What to Evaluate
The foundation of fair evaluation is choosing what to measure. Criteria should reflect what genuinely matters to your target audience, not what's easy to evaluate or what favors predetermined winners.
Audience-Driven Criteria
Start with your reader's perspective: what factors will actually influence their purchase decision? This varies by audience. Enterprise buyers care about security certifications, integration capabilities, and vendor stability. Small business buyers prioritize ease of use, pricing clarity, and quick time-to-value. Evaluate for your specific audience, not an abstract general buyer.
Research methods for identifying audience priorities include analyzing search queries related to the category (what questions are people asking?), reviewing community discussions and forums for recurring concerns, examining competitor reviews for criteria readers find valuable, and surveying your existing audience when possible.
Criteria Categories
Most tool evaluations benefit from criteria spanning multiple categories:
- Functionality: Does the tool do what users need? Feature completeness, capability depth, performance quality.
- Usability: How easy is it to use? Learning curve, interface intuitiveness, documentation quality.
- Reliability: Does it work consistently? Uptime, bug frequency, data integrity, error handling.
- Value: Is the price justified? Pricing transparency, feature-to-price ratio, hidden costs.
- Support: What happens when things go wrong? Response time, support quality, community resources.
- Trust: Can you depend on the vendor? Company stability, security practices, data privacy.
Not every evaluation needs all categories. Choose those most relevant to your audience and category. A comparison of free tools may skip pricing analysis; a security-focused comparison may weight trust heavily.
Specificity vs. Generality
Criteria should be specific enough to evaluate objectively but general enough to apply across products. “Good interface” is too subjective; “Onboarding completed in under 10 minutes without documentation” is measurable. “Number of integrations” is countable but may not reflect integration quality or relevance.
Aim for criteria that are observable (you can evaluate them during testing), comparable (applicable to all products being ranked), and meaningful (they actually affect user experience).
Weighting System: Prioritizing What Matters
Not all criteria matter equally. Your weighting system should reflect your audience's priorities, making rankings genuinely useful for their decisions.
Assigning Weights
Weights should sum to 100% across all criteria. This forces explicit prioritization—if you weight pricing at 30%, that decision has consequences throughout the evaluation. Common weighting approaches include equal weighting (each criterion counts the same, which is simple but often unrealistic), tiered weighting (primary criteria get 20-25%, secondary get 10-15%, tertiary get 5-10%), and audience-validated weighting (based on survey data or engagement analysis).
| Criterion | Budget Buyer Weight | Enterprise Buyer Weight | Rationale for Difference |
|---|---|---|---|
| Pricing/Value | 30% | 10% | Budget buyers constrained; enterprises have approval budgets |
| Ease of Use | 25% | 15% | Budget buyers self-implement; enterprises have IT support |
| Security/Compliance | 5% | 25% | Enterprises face regulatory requirements |
| Integrations | 10% | 20% | Enterprises have complex existing tech stacks |
| Core Features | 20% | 20% | Fundamental to both audiences |
| Support Quality | 10% | 10% | Important to both but not decisive |
This table illustrates how the same category might have completely different ranking outcomes depending on audience weighting. A tool with excellent security but high prices could rank #1 for enterprises and #8 for budget buyers—both rankings are fair for their respective audiences.
Documenting and Justifying Weights
Publish your weighting system. This transparency serves multiple purposes: it helps readers assess whether your priorities match theirs, it preempts criticism that rankings are arbitrary, and it forces you to articulate your reasoning.
When weights differ from obvious expectations, explain why. If you weight customer support at 25% in a category where competitors typically downplay support, explain the research or reasoning behind that emphasis.
Scoring System: Consistent Measurement
With criteria and weights established, you need a consistent scoring approach that produces comparable results across products.
Choosing a Scoring Scale
Common options include 5-point scales (simple, forces differentiation), 10-point scales (more granularity, can lead to false precision), 100-point scales (maximum granularity, often overkill), and binary pass/fail (appropriate for threshold requirements).
The right choice depends on your differentiation needs. If most products cluster together on a criterion, you may need a wider scale to distinguish them. If products are clearly different, a simpler scale suffices. Avoid using fine-grained scales if your evaluation can't actually distinguish between adjacent scores.
Developing Scoring Rubrics
Each score level needs defined meaning. A rubric prevents inconsistency where you give Product A a 7 for “pretty good” and Product B a 6 for essentially the same performance evaluated on a different day.
- Define anchor points: What does a 1 look like? A 5? A 10? Use concrete examples.
- Describe intermediate levels: What distinguishes a 6 from a 7 on this criterion?
- Include evidence requirements: What observations or data support each score level?
- Test rubric consistency: Can different evaluators apply it and reach similar scores?
Example rubric for “Ease of Onboarding” (5-point scale):
5 = Completed core setup in under 5 minutes with no documentation needed
4 = Setup completed in 5-15 minutes with minimal documentation
3 = Setup took 15-30 minutes and required reading documentation
2 = Setup took over 30 minutes or required support contact
1 = Unable to complete setup without extensive support
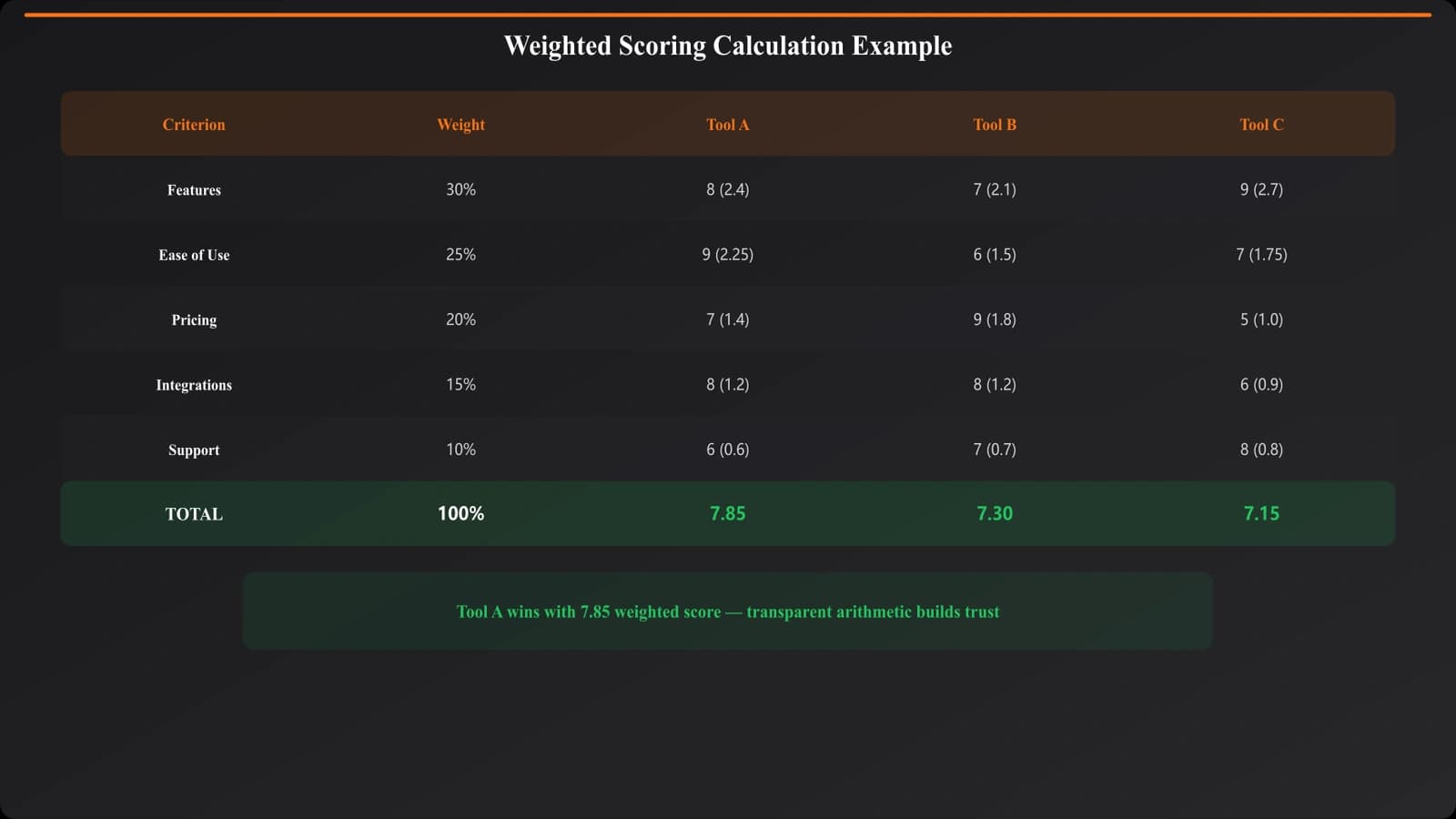
Calculating Weighted Scores
Final rankings come from weighted score totals. For each product, multiply each criterion score by its weight, then sum the weighted scores. This calculation should be transparent—readers should be able to verify your math.
Consider showing both final weighted scores and individual criterion scores. Some readers care most about the overall ranking; others want to see performance on specific criteria important to them.
Create Fair, Defensible Tool Rankings
Generate comparison pages with structured evaluation methodology that builds reader trust.
Try for FreeBias Prevention and Disclosure
Biases—conscious or unconscious—can undermine even well-designed evaluation frameworks. Proactive bias prevention and honest disclosure protect both credibility and fairness.
Common Evaluation Biases
Several biases frequently affect tool evaluations:
| Bias Type | Description | Prevention Strategy |
|---|---|---|
| Affiliate bias | Favoring products with higher commissions | Evaluate before checking affiliate terms; disclose relationships |
| Familiarity bias | Favoring products you've used longer | Test all products with equal depth; fresh-eyes evaluation |
| Brand bias | Assuming established brands are better | Blind testing phases; evaluate features not reputation |
| Recency bias | Overweighting recent experiences | Document findings systematically throughout testing |
| Confirmation bias | Finding evidence for pre-existing opinions | Define hypotheses before testing; seek disconfirming evidence |
| Halo effect | One positive aspect colors entire evaluation | Evaluate each criterion independently; rubric discipline |
Structural Bias Protections
Build bias prevention into your evaluation process:
Separation of concerns. If possible, separate commercial decisions (affiliate relationships, sponsorships) from evaluation decisions. The person evaluating products shouldn't know or consider commercial implications.
Multiple evaluators. When resources allow, have multiple people evaluate independently, then compare results. Significant disagreements warrant discussion and re-evaluation.
Pre-commitment. Document criteria, weights, and rubrics before seeing products. This prevents adjusting methodology to favor preferred outcomes.
Adversarial review. Before publishing, attempt to argue against your own ranking. If you can't defend a product's position, reconsider it.
Disclosure Best Practices
Transparency about potential conflicts builds rather than undermines trust. Disclose affiliate relationships (even if evaluation was independent), any products provided free for testing, prior relationships with vendors, and funding sources if relevant.
Also disclose limitations: which products you couldn't fully test, which features you couldn't evaluate, what audience your evaluation serves (if different from the reader's context).
Documentation and Transparency
Your methodology documentation serves as both credibility evidence and defensive documentation. Make it thorough and accessible.
Creating a Methodology Page
Consider a dedicated methodology page that applies across all your evaluations. This page should cover your general evaluation philosophy (what you prioritize and why), category-agnostic processes (how you test, document, score), team credentials and relevant expertise, and disclosure policies and conflict of interest procedures.
Link to this methodology page from each review. It provides detailed context for readers who want it without cluttering individual reviews.
In-Review Documentation
Each comparison should include sufficient methodology context for standalone reading. This includes criteria used for this specific evaluation, weighting applied and rationale, testing conditions and timeline, any category-specific methodology adjustments, and relevant disclosures for products in this comparison.
Handling Methodology Challenges
When vendors or readers challenge your rankings, documented methodology provides defense. You can point to specific criteria, show how scores were calculated, and demonstrate that the same standards applied to all products.
Welcome legitimate methodology feedback. If someone identifies a genuine flaw—a criterion you missed, a weight that doesn't reflect audience priorities—consider incorporating feedback and updating both methodology and affected rankings. Intellectual honesty strengthens rather than weakens credibility.
Implementing Your Evaluation Framework
Building a complete evaluation framework requires upfront investment, but that investment pays dividends across every review you publish.
Starting Simple
You don't need to implement everything at once. Start with core criteria definition and basic weighting for your first comparison. Add rubric documentation, bias controls, and methodology pages as you refine your process over multiple reviews.
- First review: Define 5-7 criteria, assign rough weights, document testing approach
- Second review: Develop scoring rubrics, add transparency about limitations
- Third review: Refine weights based on reader feedback, add disclosure section
- Ongoing: Build methodology page, standardize templates, add bias prevention
Maintaining and Updating
Frameworks need maintenance as categories evolve. New features become standard; pricing models change; user expectations shift. Plan for annual framework reviews to ensure criteria and weights remain relevant.
When you update methodology significantly, consider re-evaluating previous rankings. Acknowledge changes transparently: “We've updated our evaluation criteria for 2026 to include AI feature assessment, which affects some rankings from earlier reviews.”
For hands-on testing methodology, see Product Testing Methodology. For finding evaluation data, see Data Sourcing Best Practices.
Product Manager at BestPage. Pioneer in AEO research since 2024, exploring the convergence of SEO and GEO (Generative Engine Optimization). Led multiple AI-powered content optimization projects that achieved 300%+ citation increases in ChatGPT and Perplexity.